Programming challenges, uptime, and mistakes in 2013
HackerEarth hosted more than thousand
contests in the year 2013 alone. Out of them, there were more than two
dozen public programming contests by HackerEarth itself. They include our
monthly challenges and hiring challenges. There were over 200
internal and public contests by colleges in the previous year. They include
IIT Delhi, IIT Guwahati, IIT Ropar, NIT Warangal, IIIT Jabalpur, NIT Raipur,
NIT Calicut, BITS Pilani and many others. And we
have been able to do that without any sweat. But sometimes, we
made mistakes too, most of them in the early half of 2013.
####Mayhem
To tell you the truth, in the beginning it was chaotic, mayhem and scary. We
would have to monitor that everything was working right.
Sometimes, we would give in everything just to keep the site up and running.
The problem of scaling always takes a toll on you. And that too when you
want to build a word-class product. And particularly for a platform like ours
where the concept of putting more servers on demand(auto-scaling) fails due to
sudden burst in traffic, giving no time to bring more servers in action.
Below is a request graph from production server on an usual day.
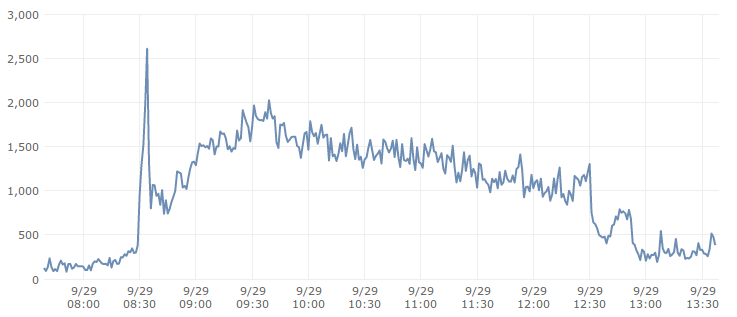
It’s important to realize that
nothing scales automatically.
100% uptime is
a constant struggle. But we were ready to roll up our sleeves and move towards
that. And in later half of 2013, things have moved ahead at a really
amazing pace. On a related note, whenever I read the
Deploying Django post by Randall
Degges, it gives me a good laugh any day. Particularly these lines:
Yes, grasshopper! You now see it: you have only begun to discover the amount
of work that lays ahead. You’ve barely scratched the surface as to the tools,
methods, and skills necessary to manage and operate even the simplest of
production sites. Your work is cut out for you.
####What We Did
We undertook a series of steps to make the experience nicer for end user:
-
We rewrote our code-checker server queueing system in early 2013 to make it asynchronous. This significantly reduced the process overhead on our frontend servers. Read more.
-
We wrote a very robust realtime server in Tornado which handles the live update of webpages. A very visible case is when you receive the result in browser on compiling/submitting the code in realtime. Read more.
-
We sharded our database and wrote database routers to reduce overhead on single database and further reduce the latency in the queries. Read more.
-
Now was the time to do some heavy stress testing of our website and we found that the results were terrible. This led to optimization of our servers and tweaking it to make it faster and resilient. Read more.
Amidst all this and contests being hosted on HackerEarth almost everyday, we had to
roll out new features whenever they were ready and as fast as possible. This
led to writing an in-house
continuous deployment system
which now allows us to put anything
in production as soon as it’s ready. Tests are run automatically and then code is deployed
in production, which keep us sane and make us brave in pushing fast.
We still mess up sometimes during
complicated deployments, which require series of steps to be done right and in
correct order. For example, when slightly complicated package dependency is required in
new commits, or when huge schema migration is required. We are working on many
aspects and have invested a lot on infrastucture and builder-tools to make sure
we don’t mess up at least 99% of the times.
####Uptime
Our uptime increased from 99.65% in April 2013 to 99.97% in November 2013. In
December 2013, we made some mistakes due to extremely fast deployment
which brought down the uptime to 99.89% in that month. From 1st
December 2013, we have alreay deployed over 500 times. Here is our uptime stats
of last 6 months:
July 2013: 99.81%
August 2013: 99.64%
September 2013: 99.98%
October 2013: 99.84%
November 2013: 99.97%
December 2013: 99.89%
The way our product is used anytime and anywhere in different timezones, we can’t
afford to shut down the site for 2 hours and do some upgradation, migration or
deployment without any care. We knew it from beginning and have invested a lot
of our time and brain in making sure everything always works smoothly.
####Monthly Challenges & Mistakes
December Monthly Challenge
- Remember December was the first challenge in last 4 months which didn’t see 100% uptime. The problem was something unexpected and baffling. The culture here is that we don’t throw servers at large number of requests and expect them to handle everything. We don’t take pride in running 100 servers. You know what, there are usually just two web-servers on which your request goes and you receive the response. We call that the frontend server. Most of the time, you are getting data from the cache. The cache is set or invalidated for each and almost many data. As of today, there are over a million key-value pairs in our memcached store. Your sessions are maintained in redis. Any other persistent data goes into MySQL or S3, but most of them are cached for some suitable lifetime. More importantly, any request that reaches our servers are made not to query the database 20 times at any point of time, whether the data is in cache or not. And when we say 20, it’s twenty. we count that. Becuase we don’t take pride in throwing more servers or databases at such problems.
In December monthly challenge, we discovered that we had defied our own rule of reading data from cache and were instead doing multiple hits to the database and S3. To make the situation worse, the read operations from S3 were expensive in terms of time. To make it even more bad, this was happening for users’ code that gets loaded in code editor for each language. Cumulatively, each visit of problem page was sending about 30 more queries to the database now and some more operations which were time and memory expensive. The ludicrous thing was that it was only happening on first time page load, as after that cache was being accessed. To salvage the situation, we threw 2-3 more servers at your requests bringing everything to normal in 16 minutes. When we found out the reason, it was due to a recent deployment of an upcoming feature. We also found out that we already had the data in the cache and didn’t even need to query the database or read from S3. But mistakes happen when you are building a complex product with a team of just 3-4 engineers, but I agree we should have been more careful.
Btw, the feature was
CodePlayer
which got announced yesterday.
####Current Architecture at HackerEarth
To give you more insights into the architecture at HackerEarth, here are the
different types of production servers that run. They might not necessarily be
on different machines, and some of them might be in multiple numbers which are
load balanced behind ELB or HAProxy, depending on the server.
- Frontend server(s)
- API server(s)
- Code-checker server(s)
- Search server(s) - Apache Solr & Elastic Search
- Realtime server - written using Tornado
- Status server
- Toolchain server (Mainly used for continuous deployment)
- Integration Test server (For integration testing of commits before deploying in production)
- Log server
- Memcached server
- Few more servers for data crunching, processing our analytics database and background jobs.
There are many other components like RabbitMQ, Celery, etc. which glues many
servers. Then there are monitoring servers, which monitor all the other servers
and also push the data to status server. Our
databases are sharded
and are load
balanced behing HAProxy. You might be interested in reading about our
technology
stack,
though it’s a bit outdated and many layers have evolved since then.
This investment in infrastructure
allows us to take more breaks and roam the streets of Bangalore
while our servers are happily
serving thousands of requests every minute.
####Dream for tomorrow
As we grow and scale further, the infrastructure and product
will even grow beyond comprehension. But from the very beginning, we
have been clear about one thing - that we will continue do this right whatever may come in
the way. And today we can proudly say that we reached 50,000 user base in a
breeze, hosted over 1000 contests and we are more stronger in our vision to solve
the problem of technical recruiting. The products in pipeline are going to
redefine many things, while our contests will become even more robust. The journey
ahead is like never before, the nights are sleepless because of the excitement.
We are here to make a dent, while singing and dancing all along the way.
‘Tis the witching hour of night,
Orbed is the moon and bright,
And the stars they glisten, glisten,
Seeming with bright eyes to listen…
…
I sing an infant’s lullaby,
A pretty lullaby.
- John Keats
P.S. If you are associated with your college programming club, reach out to me directly at vivek@hackerearth.com. Refer to this quora answer.
If you are a recruiter, do try out HackerEarth Recruit. It’s free to signup and get started with. If you face any issue, please send us an email at support@hackerearth.com and we will be in touch with you asap.
Let me know if you have any comments, suggestions or anything else.
Posted by Vivek Prakash. Follow me @vivekprakash. Write to me at vivek@hackerearth.com.