Zero to One and Beyond: HackerEarth's journey to Continuous Delivery
“Hey the deployment is broken again. Can you push this change again”
“Hey, I merged my changes were merged in the morning. I still don’t see them in production yet”
“Argh, the static files are not updated. We have to run deployment again”
These voices hollared across the hallway and this was followed by a huddle to sort things out.
These voices soon grew louder and then we realised: Our Deployment is broken.
Epilogue
At HackerEarth, we have always been good at embracing bleeding edge technologies. We have always taken pride at doing what is right and acknowledge when something needs a fix.
A faster delivery cadence and a quicker release cycle are very important for a startup of our scale. Our deployment related problems threatened our fundament need - “Pace”
This prompted us to not just fix what was broken but to introduce a new paradigm to deployment - Continuous Deployment.
The key tenets of following agile to push consistent smaller pieces of software frequently to customers and get Feedback. As any growing team, we were at one point struggling with - higher deployment failures or critical issues leaking to production. What followed was our path to redemption
Circa 2019, HackerEarth was already doing frequent deployments. We had a process to collect, merge, tag and release code into production. But, this was not enough. As it must be obvious now, our feedback cycle was not close to the point of failure. The Integration happened closer to production and any failure is now expensive to fix. This is where our journey up the CI-CD ladder begun.
You’re doing continuous delivery when:
- Your software is deployable throughout its lifecycle
- Your team prioritises keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand”
— Martin Fowler
When it all began

CI to CD in 3 steps
We decided to redraw the lines to achieve Continuous Delivery. The first step to achieve Continuous Delivery is Continuous Integration. Continuous Integration is the art of integrating different sources into a single outcome and evaluate if the combination of changes work without issues.
- This has to be done frequently and the feedback should be close to point of failure.
- The next step is Continuous Delivery. This step ensure that you not only have tested your integrations continuously but are also deploying to various environments as frequently as possible.
- The last step is Continuous Deployment where part of the product can reach customers as soon as the it is deemed fit. We were gunning for this.
The first step in our journey is Self-assessment. A honest self-assessment is important here. Unless you know what is broken, you can never be sure when is fixed. There are many methods to assess where you stand in your journey towards continuous delivery. . We built our self assessment based on the maturity model laid by Jez Humble in his book Continuous Delivery.
The model outlines a framework where you rate yourself on a scale of 0 to 3 under various parameters such as Build, Deploy, test and database.
The CI/CD Maturity Model
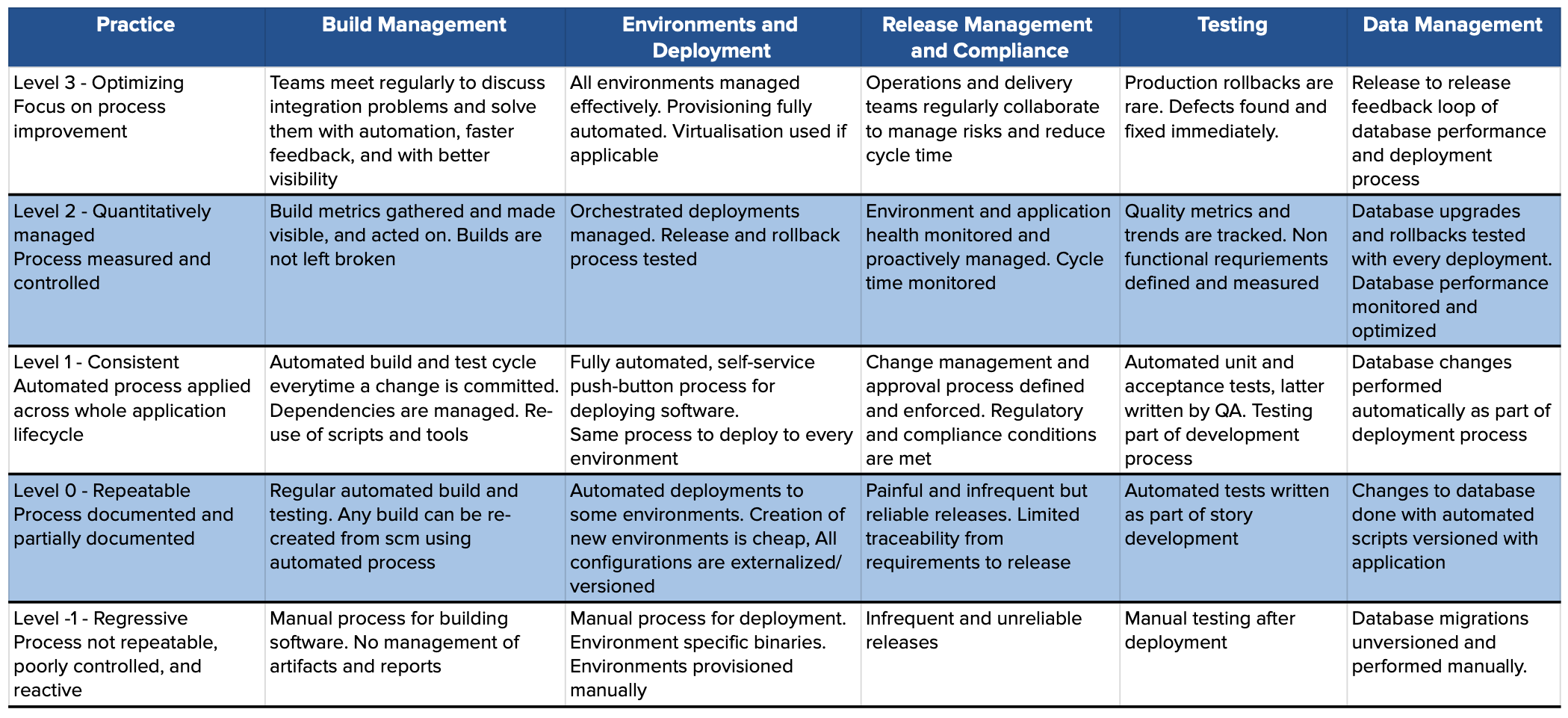
Our self assessment revealed the obvious: We score 0 across all areas that we considered.
The StrikeOut!
Take 1: Build
The biggest problem was our CI setup. Our branching and merging strategy needed a relook. We had to integrate and test our code more frequently. We need to fail first, fail fast. To achieve this we moved away from a custom integration setup to one based on orchestrator - Enter Jenkins
We created our build pipelines to run for every logical set of commits. We introduced Pull Request based merge strategy and added safety nets around each PR. The result: a green build on a PR reduced
our chances of broken trunk significantly. Each PR is not a testable artefact capable of being deployed independently in lower environment. Our build is now Repeatable, Consistent and Automated without any need for manual intervention. Strike one!
Take 2: Deploy
We extended our wins from Build strategy into deployments. We introduced a doer-checker system for compliance and also created a set of repeatable functions that were orchestrated from trunk to release to production. Deployment was de-coupled from Build and this enabled us to push any release version anytime, anywhere. We introduced Lower Environments mimicing the setup of production and thus the configurations were also similar and extensible. The result: Code can deployed to any environment without any major changes. Environments were now first class citizens. The decoupled deployments also helped us do hot-fixes without affecting regular deployment cadence. The CI tool (Jenkins) also made sure there is an audit trail. We now have build and deployment metrics. Strike two!
Take 3: Release
With the steps taken to fix deployments, accountability was already in place. We wired our Project Management system (JIRA) with our deployment orchestration. Each release was tagged and appropriate tickets were tagged with this release tag. This started giving visibility to the other stakeholders. “Hey, as my story been released yet?” was being answered. We started slow with our cadence. For our commit rate we decided on doing one deployment a day. Each candidate build was tested with automated unit and acceptance tests and approved by the QA team. We also integrated a short benchmarking step to diagnose any performance degradation (More on this later). With this we were able to reduce the deployment timelines by about 70%. Strike three!
Each of these steps involved multiple rounds of optimisations to achieve this. We also achieved a 98% rate of successful deployments.
The other tenets were Testing, Data Management and Configuration management
Testing
We had unit test written and automated acceptance tests were run.. manually. Our Build and deploy process was inclusive of testing right from the word go. The existing tests were leveraged, we had already identified means to measure quality metrics. We put in extra effort to increase our test coverage across the platform and across the test levels. Our test were environment agnostic and was able to give feedback on the state of the system as early as it can get.
Data Management
Our database is hosted in Amazon RDS and thus by nature gives an ability to deploy and rollback changes. We
made process changes to test and run database migrations in lower environments before running them in production. We added checks in the deployment system to ensure the state of database does not change with formal approval.
Configuration Management
We were actively using SCM to version code. But now extended to environment configurations, migrations deployment scripts etc. We introduced poetry for dependency management and embraced docker for containerisation. We reached a point where we followed IaaC guidelines to manage infrastructure.
The Ephiphany
- CD is a paradigm shift. Change does not happen overnight
- Embracing Continuous Deployment is a behaviroual shift. The team should move away from large deployments to smaller shorter release cycles. This also means establishing a sturdy safety net to catch failures at each step.
Embrace DevOps culture - This requires the teams to abolish silos and work as cross-functional teams. Treat your test code and test infrastructure as first class citizens.
Invest on Feature Flags
Feature flags/Feature toggles have been in use for a while. Start using these to push changes to trunk without affecting customer usage. Avoid long running feature branches.
Improve - continuously
Start measuring your build and deploy metrics. Pick up north start metric around each tenet and work towards moving the needle. Celebrate small wins, every input to get there counts.
Accelerate!
We assessed ourselves every quarter to see where we stand. And we now stand at level 2 raring to go to level 3.
How do we get there? Accelerate!
Continuous Delivery is also a behavioural change. Now the team is ready we adopt the “Accelerate” metrics or 4 Key metrics to measure and improve. The key metrics being: Lead Time, Deployment Frequency, Mean time to Recovery, Change fail percentage. Stay tuned for more updates from our rocket-ship as we discover what lies ahead of us.
Posted by Navaneethakrishnan R, Director of Quality Engineering