Smart suggestions with Django, Elasticsearch and Haystack
Introduction
One of the primary issues when gathering information from users is suggesting the right options that they are looking for. At HackerEarth, we gather information from all our developers which help us provide them a better experience. So there came a time when we had to suggest very smartly to our users! :D
When humongous amounts of data has to be indexed and suggested intelligently, one of the efficient ways to do it is by using an inverted index. An inverted index basically is a map of words that appear in documents to a list of documents the word is found in. Popular Lucene based search servers like Elasticsearch and Solr are tools to maintain large inverted indexes and provide an efficient means to look up documents.
Here is an example from the profiles page on HackerEarth.
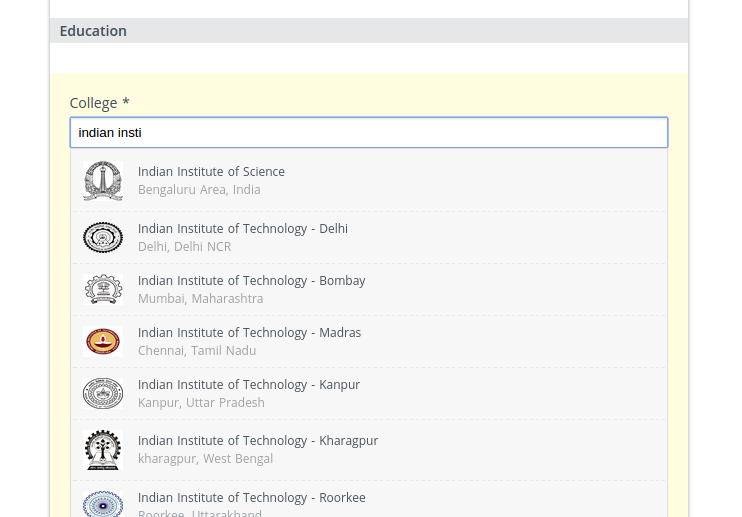
We use Elasticsearch to index millions of documents with various fields. Two hurdles to be crossed while solving this problem are latency and relevance. Relevent documents have to be suggested to the user while keeping the time taken to retrieve them (ie. latency) as low as possible. Elasticsearch uses analyzers that help in achieving good relevence, but only if used in a witty manner. It also allows us to build our own custom analyzers. So by assaying the user input, astute analyzers can be built to increase relevance. A simple example for a document can be something like,
{
'_id' : 'AVJUN6QaLYvICHZxvYEq',
'username': 'ksrvtsa',
'location': 'Bangalore',
'hobbies': ['music', 'reading', 'hiking'],
}
So what are analyzers?
An analyzer converts the text to be indexed and creates lookups for finding the text when needed using appropriate search terms. An analyzer is composed of a tokenizer that splits your text into multiple tokens which is followed by many token filters which modify, delete or add new tokens. The tokenizer can be preceded by character filters which modify the text before passing it to the tokenizer.
Every field in a document has an index analyzer and a search analyzer. The index analyzer is used while the text for that field is being indexed for a particular document. And the search analyzer is used when a search is being made for documents based on that particular field. These analyzers for all the fields can be provided using the mapping for the particular index type in the index. Various combinations of these tokenizers, token filters and character filters can be used to build custom analyzers in the settings. An example of a mapping and a setting are,
"mappings": {
"user": {
"properties": {
"username": {
"type": "string",
"index_analyzer": "name_analyzer",
"search_analyzer": "standard"
},
"email_stub":{
"type": "string",
"analyzer": "name_analyzer"
}
}
}
}
"settings": {
"analysis": {
"filter": {
"custom_ngram": {
"type": "nGram",
"min_gram": 3,
"max_gram": 10,
},
"custom_edge_ngram":{
“type: “edgeNGram”,
“min_gram”: 4,
“max_gram”: 8,
“side”: left
},
},
"analyzer": {
"name_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["custom_ngram"]
},
"name_edge_analyzer": {
“type”: “custom”,
“tokenizer”: “standard”,
“filter”: [“custom_edge_ngram”]
}
}
}
}
By default Elasticsearch uses the Standard analyzer for indexing and searching. The Standard analyzer comprises of Standard Tokenizer with the Standard Token Filter, Lower Case Token Filter, and Stop Token Filter. It splits the text on spaces and converts all tokens to lowercase.
An example of its usage
curl 'localhost:9200/_analyze?analyzer=standard&pretty' -d 'This is HackerEarth'
{
"tokens" : [ {
"token" : "this",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 1
}, {
"token" : "is",
"start_offset" : 5,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 2
}, {
"token" : "hackerearth",
"start_offset" : 8,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 3
} ]
}
Notice that the text is split on space and the converted to lowercase.
So the tokens generated are ‘this’, ‘is’, ‘hackerearth’, but unless the user queries with these words Elasticsearch will not look up the document. So to increase the discoverability and the relevancy of the search Ngrams and Edge Ngrams are used. The topic below explains them in detail.
Elasticsearch provides many filters, tokenizers and analyzers. So go ahead and read about them as Elasticsearch gives complete freedom to mash them up to build our own analyzers.
The secret sauce!
Ngrams and Edge Ngrams are the secret ingredients when it comes to suggesting the right document based on a user query. So what are they? Wikipedia explains Ngrams as a contiguous sequence of n items from a given sequence of text or speech. They are basically a set of co-occurring letters in a piece of text in the case of Elasticsearch. For example,
If N = 4, and the text is 'hackerearth', the ngrams generated are,
’hack’ ‘acke’ ‘cker’
‘kere’ ‘erea’ ‘rear’
‘eart’ ‘arth’
Elasticsearch provides both, Ngram tokenizer and Ngram token filter which basically split the token into various ngrams for looking up.
In the above shown example for settings a custom Ngram analyzer is created with an Ngram filter. If you notice there are two parameters min_gram and max_gram that are provided. These are the min and max sizes of the ngrams that are to be generated for the lookup tokens. For example,
If min_gram = 4 and max_gram=6, and the text is “hackerearth”, the ngrams generated are,
’hack’ ‘acke’ ‘cker’ ( N = 4 )
‘kere’ ‘erea’ ‘rear’
‘eart’ ‘arth’
‘hacke’ ‘acker’ ’ckere’ ( N = 5 )
‘kerea’ ‘erear’ ‘reart’
‘earth’
‘hacker’ ‘ackere’ ‘ckerea’ ( N = 6 )
‘kerear’ ‘ereart’ ‘rearth’
If you notice the ngrams are generated for size 4, 5 and 6.
The only difference between Edge Ngram and Ngram is that the Edge Ngram generates the ngrams from one of the two edges of the text which will be used for the lookup. Elasticsearch provides an Edge Ngram filter and a tokenizer which again do the same thing, and can be used based on how you design your custom analyzer. Edge Ngrams take an extra parameter “side” which denotes the side of the text from which the ngrams have to be generated, an example is provided in the settings above. An edge ngram example,
If the text is ‘hacker’, min_gram is 2, max_gram is 6 and side is left.
The ngrams generated are,
‘ha’, ‘hac’, ‘hack’, ‘hacke’, ‘hacker’
So for an intelligent way to suggest documents to the user, Ngrams or Edge Ngrams can be used to create custom analyzers for indexing and querying on the fields of the document type.
Deployment
For deployment, we have used Haystack to index the models and query the index. Haystack provides an easy way of creating, updating, building and rebuilding indexes. Since some of the fields require their own analyzers for indexing and searching, we have created custom fields for the search indexes.
from haystack import indexes
from dummy_app.models import Dummy
class CustomNgramField(indexes.CharField):
field_type = 'ngram'
def __init__(self, **kwargs):
if kwargs.get('search_analyzer'):
self.search_analyzer = kwargs['search_analyzer']
del(kwargs['search_analyzer'])
if kwargs.get('index_analyzer'):
self.index_analyzer = kwargs['index_analyzer']
del(kwargs['index_analyzer'])
super(CustomNgramField, self).__init__(**kwargs)
class DummyIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
dummy_field = CustomNgramField(model_attr='dummy_field',
index_analyzer='analyzer_1',
search_analyzer='analyzer_2')
def get_model(self):
return Dummy
def index_queryset(self, using=None):
return Dummy.objects.all()
And now for creating our own custom analyzers, we have overridden the build_schema function by creating a custom backend for Elasticsearch. The ElasticseachSearchBackend is inherited and the ‘DEFAULT_SETTINGS’ parameters can be set with our custom Elasticsearch settings. This creates all our custom analyzers for usage.
from haystack.backends import BaseEngine
from haystack.backends.elasticsearch_backend import ElasticsearchSearchBackend
from haystack.backends.elasticsearch_backend import ElasticsearchSearchQuery
from myapp.settings import CUSTOM_ELASTIC_SETTINGS
class CustomElasticSearchBackend(ElasticsearchSearchBackend):
def __init__(self, connection_alias, **connection_options):
super(CustomElasticSearchBackend, self).__init__(connection_alias,
**connection_options)
setattr(self, 'DEFAULT_SETTINGS', CUSTOM_ELASTIC_SETTINGS)
def build_schema(self, fields):
content_field_name = ''
mapping = {}
content_field_name, mapping = super(CustomElasticSearchBackend,
self).build_schema(fields)
for field_name, field_class in fields.items():
field_mapping = mapping[field_class.index_fieldname]
if hasattr(field_class, 'index_analyzer'):
field_mapping['index_analyzer'] = field_class.index_analyzer
if 'analyzer' in field_mapping:
del(field_mapping['analyzer'])
if hasattr(field_class, 'search_analyzer'):
if 'analyzer' in field_mapping:
del(field_mapping['analyzer'])
field_mapping['search_analyzer'] = field_class.search_analyzer
mapping[field_class.index_fieldname] = field_mapping
return (content_field_name, mapping)
class CustomElasticsearchSearchEngine(BaseEngine):
backend = CustomElasticSearchBackend
query = ElasticsearchSearchQuery
Now that all of this is setup, index your data and suggest smartly!
Going ahead, we plan to deploy this site wide and make suggestions better by analysing the user input for creating new options in the dropdowns.
Send an email to support@hackerearth.com for any bugs or suggestions.
Posted by Karthik Srivatsa