The Robust Realtime Server
This is going to be a long blog post but I promise you will find some interesting piece of engineering here, so stay till the end.
The realtime server manages the live update of webpages when the data changes
in the data storage system (database or cache). We had a realtime server
in-place but there was a big problem with scaling it.
####Problem with nowjs
I was told beforehand that I will be primarily working first on writing a realtime server
beside many other things. Vivek Prakash told me he had
written a realtime server implementation sometime
ago with
nowjs. But the problem with it is that it
doesn’t scale well beyond ~200 simultaneous connections. In a conversation on
Google Groups, I came across this:
In my experience, the underlying “socket.io” module is not able to scale well
(more than 150 connections was a problem for me), so I had to retreat from
using “nowjs” or more specifically, “socket.io” in one of my applications.
After further inspection, we also saw that there was an issue with file
descriptor leak and nowjs server reported ENFILE/EMFILE (Too many open files).
Also nowjs project was abandoned in 2012 and last commit in github repo is that
of 1 year ago.
So there was need of some good alternative
which can handle large number of simultaneous connections (or users). I didn’t have to do much research
as Vivek had already researched about it. He found Tornado and Meteor.js to be good
alternative. Going by order of preference and popularity I chose Tornado, and
also because it’s integration with existing system looked simpler and more
efficient.
####The Use Case
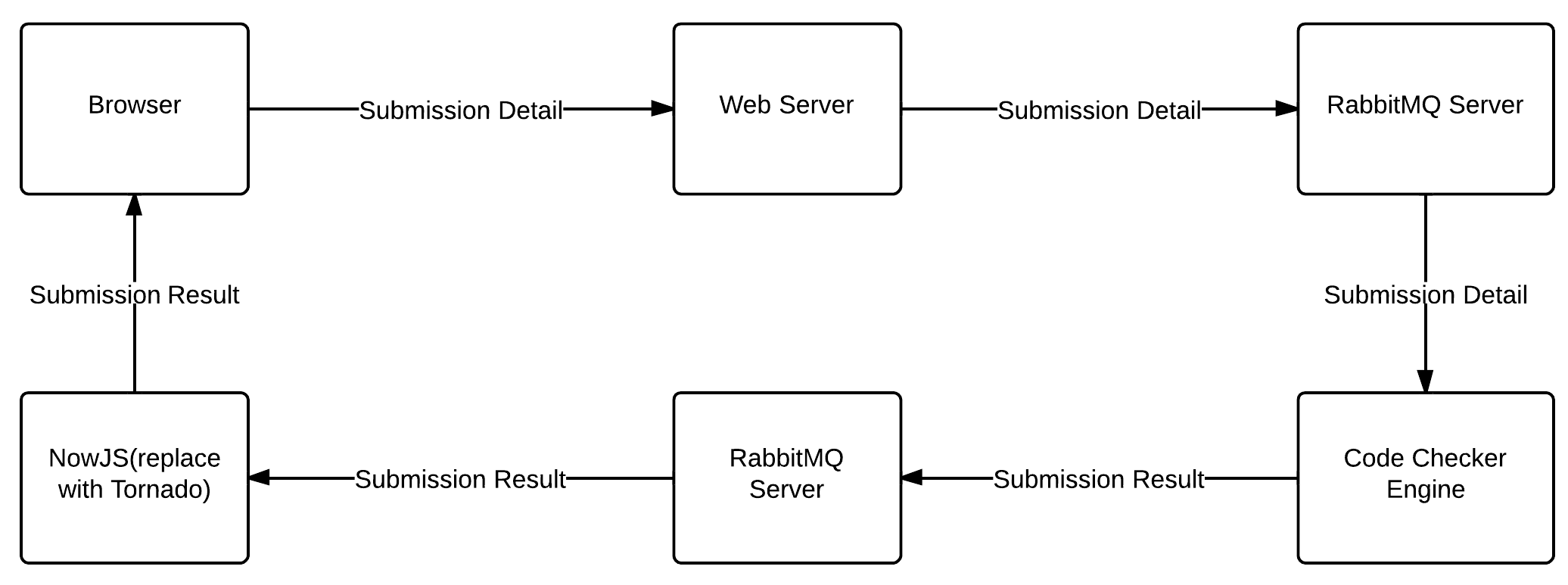
Vivek pretty much explained me how different components of code
submission works. Here is a quick explanation of it. User submits the code
and a POST request is sent to webserver which further sends submission details
to a message queue in RabbitMQ server (a message broker to connect various application components).
Code-checker engine (consumer of RabbitMQ here) gets the submission details,
evaluates the code and submits result back to another message queue. It also
notifies the web-servers about the result so that appropriate databse entry is
made. The whole process is completely asynchronous. An amqp listener also takes
the result out from message queue and finally sends it to the client(browser)
using the nowjs communication APIs. The flowchart
will give you a good idea of how different components are connected.
Now my first job was to replace the nowjs module with Tornado.
####A basic implementation
Let’s code! Now I knew tornado server must read submission results from
message queue and send it back to submission page (‘pages’ in case user has opened
the same submission problem page in more than one tab). I used pika
module
inside Tornado IO loop to connect with RabbitMQ and read messages from it.
On client side I used HTML5 WebSocket
to connect to the tornado server. This basic implementation was completed in two days.
#####Frontend *(code snippet)*
...
function openWebSocketConnection() {
var ws = new WebSocket(url);
// On websocket open
ws.onopen = function() {
clientInfo = {
'name': getName()
}
clientInfo = JSON.stringify(clientInfo);
ws.send(clientInfo);
}
// On recieve message from server
ws.onmessage = function(evt) {
onReceiveMessage(JSON.parse(evt.data));
};
}
...
#####Backend (code snippet)
...
class RealtimeWebSocketHandler(websocket.WebSocketHandler):
def on_message(self, message):
'''
Messages recieved from client
'''
message = json.loads(message)
self.name = message['name']
#listen to submission result messages from rabbitmq
self.application.pc.add_listener(self)
...
def on_close(self):
#remove listener
self.application.pc.remove_listener(self)
def send(self, message):
'''
Send response back to client
'''
self.write_message(message)
class PikaClient(object):
def connect(self):
'''
Connect to RabbitMQ Sever
'''
...
def on_message(self, channel, method, header, body):
'''
Submission result messages from RabbitMQ
'''
message = json.loads(body)
self.notify_listeners(message)
...
def notify_listeners(self, message):
listeners = self.listeners.copy()
for listener in listeners:
#send message to specific listener
if listener.name==message['name']:
listener.send(message)
...
####Testing locally
Everything was working as expected in modern browsers but
when I tested it on IE 7, 8, 9. This was my reaction- “IE sucks man!”.
Of course, IE doesn’t support websocket, how it
didn’t occur to me. So I was left with only one option to write a fallback
implementation in long polling (also called comet programming)
on both client and server side. Wait the problem is not yet solved. Cross domain requests are not supported.
HackerEarth webserver and realtime server (tornado) are on different top-level domains. I either have to use
CORS long polling
(only supported in major browsers but more secure) or JSONP
long polling(supported in every browser but insecure). I eventually used both.
Here is a code snippet:
#####Frontend
function connectToTornado() {
// check for browser's websocket support
if("WebSocket" in window) {
openWebSocketConnection();
}
// fallback to cross origin requests(CORS) long polling
else if($.support.cors || "XDomainRequest" in window) {
openCORSLongPollingConnection();
}
// fallback to jsonp long polling
else {
// setTimeout is used to supress loading sign
// in some old browsers.
setTimeout(openJSONPLongPollingConnection, 1);
}
}
function openCORSLongPollingConnection() {
$.ajax({
...
data: {
'name':getName()
},
dataType: "json",
success: function(data) {
onReceiveMessage(data);
// connect again to recieve new messages
window.setTimeout(openCORSLongPollingConnection, 0);
},
...
});
}
function openJSONPLongPollingConnection() {
$.ajax({
...
data: {
'name':getName(),
'callback':'success' // **do not delete this line**
},
dataType: "jsonp", // must for jsonp
jsonp: false,
jsonpCallback: 'success', // **do not delete this line**
success: function(data) {
onReceiveMessage(data);
// connect again to recieve new messages
window.setTimeout(openJSONPLongPollingConnection, 0);
},
...
});
}#####Backend
class RealtimeLongPollingHandler(web.RequestHandler):
@tornado.web.asynchronous
def post(self):
self.transport = 'cors'
self.name = urllib.unquote(self.request.body.split('=')[1])
self.application.pc.add_listener(self)
@tornado.web.asynchronous
def get(self):
self.transport = 'jsonp'
self.name = self.get_argument('name', None)
self.callback = self.get_argument('callback', None)
self.application.pc.add_listener(self)
def on_connection_close(self):
self.application.pc.remove_listener(self)
def send(self, message):
if(self.transport=='jsonp' and self.callback is not None):
self.finish(self.callback+'('+json.dumps(message)+')')
elif(self.transport=='cors'):
self.finish(message)
self.application.pc.remove_listener(self)
####What if the client gets disconnected?
On slow internet connections especially with browsers using long polling,
messages sometimes get lost. So I had to create a buffer to store unsent
messages and when client(browser) reconnects, the server will look into
the buffer for latest message and will send it back to client and then again it
will listen for new messages from RabbitMQ. Here is code snippet:
#####Reconnect with tornado *(JavaScript)*
function reconnectToTornado(callback) {
// Sleep time is constant after 5 minutes
if(errorSleepTime<300000)
errorSleepTime *= 2;
// callback can be websocket, cors, jsonp function
window.setTimeout(callback, errorSleepTime);
}
#####Look for unsent messages *(Python)*
...
newest_message = self.application.pc.unsent_messages.newest(self.name)
if(newest_message is not None):
self.send(newest_message)
else
self.application.pc.add_listener(self)
...
class UnsentMessageBuffer(object):
def __init__(self):
#unsent messages deque with capacity of 1000 objects
self.messages = collections.deque([], maxlen=1000)
def add(self, message):
self.messages.append(message)
def remove(self, message):
try:
self.messages.remove(message)
except:
pass
def newest(self, client_name):
messages = copy.deepcopy(self.messages)
newest_message = None
for message in messages:
if(message['name']==client_name):
if(newest_message is None or message['id']>newest_message['id']):
newest_message = message
self.remove(message)
return newest_message
It was also taken care of that older messages don’t replace the newer messages
on browser if the delivery order is not sequential. I also wrote lot of
fallback code to prevent the issue in older browsers, did testing with thousand
simultaneous connections and fixed some bugs that were already present before.
And that’s all that I did in just two weeks! Everything was working fine in my
local machine now.
Few days ago, we tested it on development server. And after successful
testing and few more bug fixes, it was pushed to production on 30th May, 2013 :)
Some bugs still might be there and we are fixing them, but I am confident it
would be more robust than ever before!
P.S. I am an undergraduate student at IIT Roorkee. You can find me @LalitKhattar or on HackerEarth.
Posted by Lalit Khattar, Summer Intern 2013 @HackerEarth