Computing accurate skill percentile with DDSketch
Introduction
HackerEarth has lots of candidates getting evaluated on a daily basis. We have a feature that benchmarks candidates across the platform. Benchmarking is the process of creating the profile of the ideal candidate for a position, and then measuring all candidates against that profile. To benchmark candidate skills against our millions of candidates, we decided to move away from our regular cron solution to build a more reliable and accurate data pipeline. To support this, we created a new data ingestion flow and data read flow. We moved away from our deterministic algorithms to probabilistic algorithms with DDSketch.
Problem
Our old benchmarking solution was trying to compute the global benchmarking of a candidate on the fly by calculating the solve percentage of the individual skills and returning the geometric mean of all the skill benchmarks. We handle huge volumes of data every day. Analyzing this data itself—for example, calculating a quantile was optimal in terms of resources.
Solution
We came up with a solution that computes an approximate quantile from a compressed representation of that data. We first need to appropriately summarize that data without incurring an excessive loss of fidelity. We do this by creating a sketch. Sketch algorithms generate sketches: smaller, more manageable data structures, from which we can calculate some properties of the original data.
We considered various algorithms to accurately compute percentiles on noisy, large-scale, real-time data that we were receiving from candidates’ skill scores. We considered using Tdigest and DDSketch. For our use case, DDSketch served the purpose.We did a POC and compared the accuracy of both the algorithms as shown below to come up with a finalized algorithm.
POC results and observations
We compared the actual percentile ranges in comparison to the two probabilistic approaches we mentioned(DDSketch and T-DIgest), and these were the results. Note: we have run these tests on the random data samples from the POC point of view.
Initial sample size: 1000(unbiased)
New sample size: 2% of actual samples i.e., 20
actual_percentile_thresholds:
{'p99': 99.1, 'p97': 97.56, 'p95': 96.31, 'p90': 91.37, 'p85': 80.44, 'p80': 80.44, 'p75': 75.79, 'p70': 71.27}
percentile_thresholds_ddsketch:
{'p99': 98.5, 'p97': 98.5, 'p95': 96.55, 'p90': 90.93, 'p85': 80.65, 'p80': 80.65, 'p75': 75.95, 'p70': 71.53}
Deviation for ddsketch:
{'p99': 0.61, 'p97': -0.96, 'p95': -0.25, 'p90': 0.48, 'p85': -0.26, 'p80': -0.26, 'p75': -0.21, 'p70': -0.36}
Deviation for tdigest:
{'p99': -0.08, 'p97': -0.03, 'p95': 0.0, 'p90': -0.02, 'p85': -0.01, 'p80': -0.01, 'p75': 0.0, 'p70': -0.21}
--------------------------------------------------------------------------------
Initial sample size: 500(unbiased)
New sample size: 2% of actual samples i.e., 10
actual_percentile_thresholds:
{'p99': 99.18, 'p97': 96.88, 'p95': 94.98, 'p90': 90.79, 'p85': 80.95, 'p80': 80.95, 'p75': 75.65, 'p70': 70.55}
percentile_thresholds_ddsketch:
{'p99': 98.5, 'p97': 96.55, 'p95': 94.64, 'p90': 90.93, 'p85': 80.65, 'p80': 80.65, 'p75': 75.95, 'p70': 70.11}
percentile_thresholds_tdigest:
{'p99': 99.33, 'p97': 97.0, 'p95': 94.99, 'p90': 90.84, 'p85': 80.97, 'p80': 80.97, 'p75': 75.83, 'p70': 70.58}
Deviation for ddsketch:
{'p99': 0.69, 'p97': 0.34, 'p95': 0.36, 'p90': -0.15, 'p85': 0.37, 'p80': 0.37, 'p75': -0.4, 'p70': 0.62}
Deviation for tdigest:
{'p99': -0.15, 'p97': -0.12, 'p95': -0.01, 'p90': -0.06, 'p85': -0.02, 'p80': -0.02, 'p75': -0.24, 'p70': -0.04}
--------------------------------------------------------------------------------
Initial sample size: 5000(unbiased)
actual_percentile_thresholds:
{'p99': 99.23, 'p97': 97.25, 'p95': 95.25, 'p90': 90.24, 'p85': 81.05, 'p80': 81.05, 'p75': 76.16, 'p70': 71.07}
percentile_thresholds_ddsketch:
{'p99': 98.5, 'p97': 96.55, 'p95': 94.64, 'p90': 90.93, 'p85': 80.65, 'p80': 80.65, 'p75': 75.95, 'p70': 71.53}
percentile_thresholds_tdigest:
{'p99': 99.23, 'p97': 97.25, 'p95': 95.23, 'p90': 90.24, 'p85': 81.08, 'p80': 81.08, 'p75': 76.1, 'p70': 71.08}
Deviation for ddsketch:
{'p99': 0.74, 'p97': 0.72, 'p95': 0.64, 'p90': -0.76, 'p85': 0.49, 'p80': 0.49, 'p75': 0.28, 'p70': -0.65}
Deviation for tdigest:
{'p99': 0.0, 'p97': 0.0, 'p95': 0.02, 'p90': 0.0, 'p85': -0.04, 'p80': -0.04, 'p75': 0.08, 'p70': -0.01}
From above calculations we can deduce that, the percentile deviation in tdigest is close to actual percentile deviation i.e(< 0.2 %), whereas the percentile deviation in ddsketch is approx (< 0.6 %) which is still very accurate to the actual percentile.
We further did a time and space complexity analysis for both the algorithms.Below were the observations.
Sample size: 1000
Time taken to add samples to sketch(DDSketch): 4.124 ms
Time taken to add samples to tdigest: 76.15 ms
sample size: 10000
Time taken to add samples to DDSketch: 27.54 ms
Time taken to add samples to TDigest: 658.18 ms
sample size: 100000
Time taken to add samples to DDSketch: 298.89 ms
Time taken to add samples to TDigest: 7243 ms -> 7.243 sec
Based on the above calculation, we can see that for same sample size (100000) of data DDSketch 298.89 ms to calculate the sketch with deviation of <0.6% from actual percentile and TDigest takes 7.243 sec with 0.2% deviation from actual percentile.
Serialized object size Comparison: As sketch or digest objects will be stored as serialized files, we also calculated the size of the objects
Sample size: 1000
Size of serialized DDSketch object: 4127 bytes
Size of serialized TDigest: 10015 bytes
sample size: 10000
Size of serialized DDSketch object: 5138 bytes
Size of serialized TDigest: 17496 bytes
sample size: 100000
Size of serialized DDSketch object: 6224 bytes, at relative accuracy(0.01)
Size of serialized TDigest: 22049 bytes, at relative accuracy(0.01)
POC Conclusion
Based on the above calculation, we can conclude that TDigest gives less deviation to accurate percentiles in comparison to DDSketch, consuming more memory and time. Whereas in our case, we can afford to have accuracy with deviation close to 1%, time and memory plays an important role in faster calculations of sketches.
Hence, we went with the DDSketch algorithm which takes a nominal time and memory for creating sketches.
Data Ingestion Pipeline (Improved Architechture)
Now that we know that we need to create sketches, we need to create new sketches for every new data point regularly coming from millions of candidates taking tests at our platform. We needed a data ingestion pipeline for updation of these sketches in near real time.
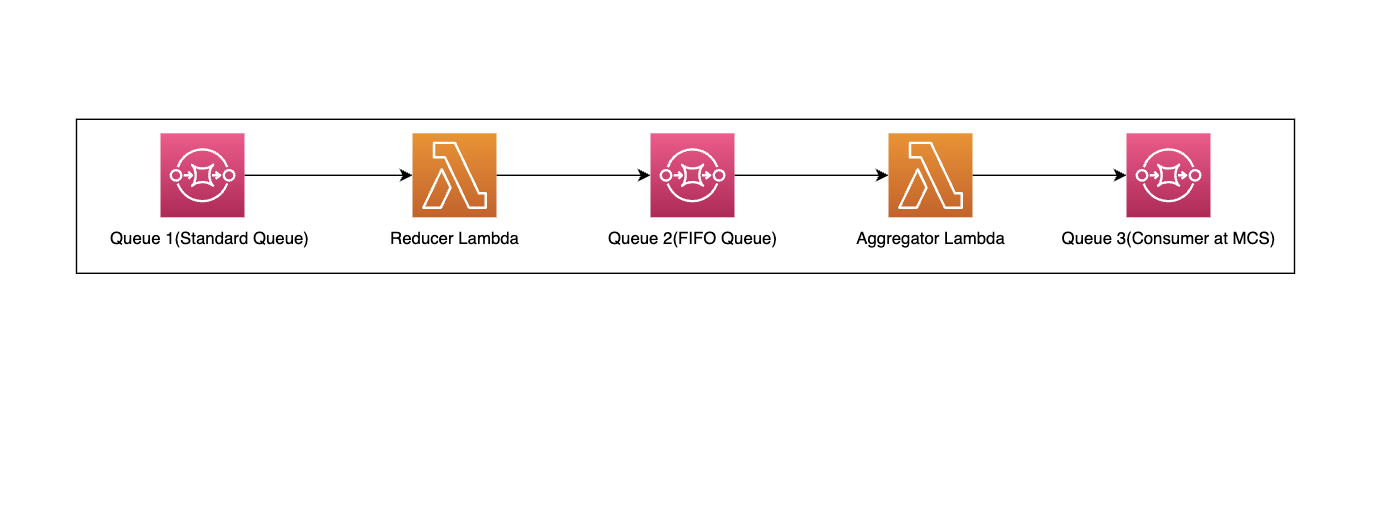
We built a data pipeline to update the sketch. Individual candidate skills and scores were stored in dynamo DB. Participation end triggers the data from Dynamo db to the map-reduce flow ; the candidates skill data is consumed by reducer SQS queue. Reducer lambda takes data in batches of 10000 or 5 mins time intervals and reduces the data to skill-wise scores. These messages are then consumed by the SQS FIFO queue, which groups the data based on problem template and skills. This data is again consumed by the sketch update lambda, which generates the new sketch, merges the new skill sketch with the old sketch, and then calculates the percentile threshold. This flow in turn is consumed by the SQS queue which updates the data in the SQL table.
Model for Storing the Percentile Threshold:
Class ProblemsPercentileThreshold(Base, Generic):
"""
Model to store the percentile thresholds of a problem.
"""
percentile_thresholds = JsonField()
denominator = models.IntegerField()
sketch_file = models.FileField()
users_attempted = models.IntegerField() # approach 4
last_updated_timestamp = models.DateTimeField()
Script to do the initial precomutaion:
# DDSketch
from ddsketch import DDSketch
from ddsketch.pb.ddsketch_pb2 import DDSketch as DDSketch_PB
from ddsketch.pb.proto import DDSketchProto
sketch = DDSketch()
for score in normailzed_scores:
sketch.add(score)
# to serialize to string and store sketch
protobuf_obj = DDSketchProto.to_proto(sketch)
data = protobuf_obj.SerializeToString()
# to deserialize back to obj
protobuf_obj = DDSketch_PB()
protobuf_obj.ParseFromString(data)
sketch = DDSketchProto.from_proto(protobuf_obj)
###############################################################################################
#T-digest
from tdigest import TDigest
digest = TDigest()
digest.batch_update(normailzed_scores)
# to serialize to json
data = json.dumps(digest.to_dict())
# to deserialize
digest_dict = json.loads(data)
digest = TDigest()
digest.update_from_dict(digest_dict)
Conclusion
We built global_benchmarking to reliably and effectively run resource-intensive and time-intensive percentile calculations asynchronously in the background. It is now responsible for running asynchronous flows for supporting benchmarking analysis on 1 million or more candidates. This is a beneficial insight for enabling recruiters to make best decisions as well as enabling candidates to improve their skill set.
Posted by [Raunak choudhary] (https://www.linkedin.com/in/raunak-chowdhary-b49406b1)