Analyzing submissions in real time for social media updates
Objective
In Jan 2015, HackerEarth conducted nearly 10-12 hiring challenges, 5-6 coding challenges and numerous college challenges. HackerEarth has a decent social media presence and we wanted to inform our followers about the events at HackerEarth. One of the main objectives of this project was to provide flexibility to the marketing team to automate simple jobs and to focus on sophisticated campaigns.
Design Goals
As a first step, we decided to post about our events and their highlights on twitter. We covered event reminders, start/end of contests, who scored first AC and leaderboard updates at the end of a contest. We chose to do it by reading from the biggest and the meanest table of our database of Submissions.
Challenges
The submissions table is a very large table. An additional query on the submissions table during peak hours was not favourable. Hence, we did not count the submissions in-place and instead queued them to be processed later.
Preventing duplicate tweets while maintaining state is also a challenge.
Solution
The application made a high volume of reads, few writes/updates. So any key/value stored would do the job. We chose Redis in lieu of Memcached.
- Redis offers data persistence in the event of node failure. This is very useful to avoid duplicate tweets. For instance, Two different users being credited for first AC submission in an event.
- By setting key expiry time and less number of keys for a single event, we prevented our Redis server from being overloaded.
- We maintained a key in Redis to keep count of submissions for an event. Reading from the database was not recommended because it would make a read call per submission during peak time and Redis performed faster reads.
The application is an asynchronous worker and payload containing submission_id and event_id are passed to it using Kafka.
So when the Redis key counter hit the magic numbers (1, 100, 500, multiples of 1000), The worker makes a DB query and posts a tweet.
Worker subscribes to a Kafka broker on the submission topic to receive the payloads pertaining to it.
Here is the code of the worker.
class ConsumePostTweets(KafkaConsumer):
def __init__(self):
routing_key = KafkaConsumer.KAFKA_SUBMISSION_TOPIC
self.redis_cache = get_redis(
settings.REDIS_DATA_CONNECTION_URL)
super(ConsumePostTweets, self).__init__(routing_key)
def on_message(self, body):
message = json.loads(body)
submission_id = message.get('submission_id')
if submission_id is None:
autocommit_transaction()
return
try:
message = json.loads(body)
message.update({"redis_cache": self.redis_cache})
process_tweets(**message)
autocommit_transaction()
except Exception, e:
log_tags = ["tweets", "queue", "consumer", str(submission_id)]
tb = traceback.format_exc()
silo.log(tb, tags=log_tags, type="LiveTweeter")
autocommit_transaction()
We also run a Cron job to post event reminders.
def post_challenge_reminder():
"""Task to post challenge reminders.
"""
now = datetime.now()
later_1_hour = now + timedelta(hours=1)
events = Event.objects.filter(
Q(start__gt=now) & Q(start__lte=later_1_hour))
events = [event for event in events if is_tweet_allowed_for_event(event)]
for event in events:
tweet_grammar = random.choice(grammar.CHALLENGE_REMINDER_FEEDS)
post_tweet(tweet_grammar, event)
As the number of challenges in a time slot increased, we needed to lower the number of tweets in a particular time interval. We queued our tweet payloads with a delay and posted them at intervals.
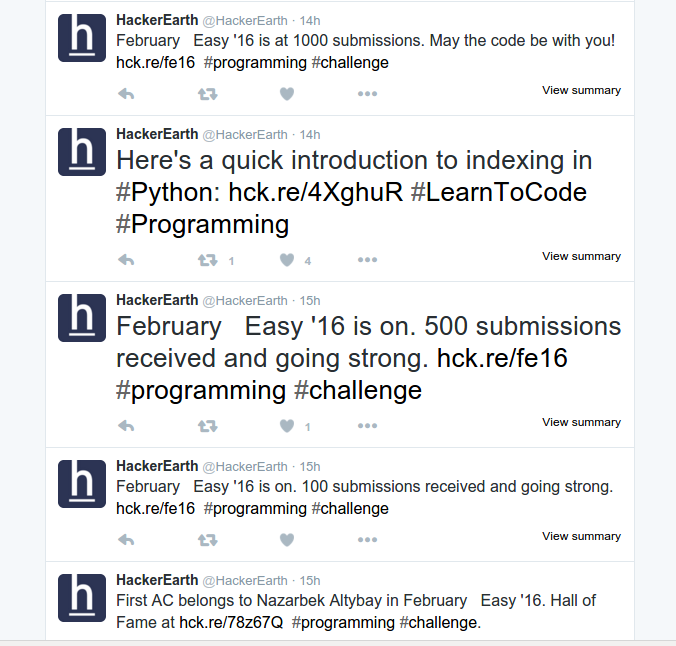
Here is a screenshot of the app in production.
Epilogue
Finally, we wrapped it as a valentine’s day gift for the marketing team and they have been loving us more since that day.
Send an email to support@hackerearth.com for any bugs or suggestions. Posted by Sreeram Boyapati