Post-mortem: The big outage on January 25, 2014
25th January was a rather unfortunate day for us. The monthly challenge - January Jackpot 2014 which was scheduled at 9:30 PM that day was cancelled due to turn of events going wrong at the worst possible time. We regret once again for the incovenience caused to you, and this is a postemortem of what really happened behind the scenes.
It was Saturday, and the day was sunny here. Everything was running smoothly as usual. The whole HackerEarth team was out roaming in Bangalore, went to a lake, did boat ride, went for a lunch then and came back to office in evening. We all sang with the guitar and played counter strike. At the same time, there was a college contest - Epiphany January Challenge going on. Everything was smooth, the servers were sending replies happily and we didn’t have to worry about anything.
This is the email I received in the evening from Ravi from NIT Surat who handles the coding contests there.
from: Ravi Ojha
to: Vivek Prakash
date: Sat, Jan 25, 2014 at 7:37 PM
First, Thank You for HackerEarth!! Its such a lucid platform for organizing
online contests. <br> ####How it went wrong Little did we know that there was a catastrophe waiting for us in the contest that was going to run at 9:30 PM. First let me assure you that the last thing we need to worry about is the number of requests that hit our servers. Read [Scaling Python/Django application with Apache and mod_wsgi](http://engineering.hackerearth.com/2013/11/21/scaling-python-django-application-apache-mod_wsgi/) to understand why.
And in this case, there were not many as the website had stopped respoding anyway. Here is the request graph of last one week:
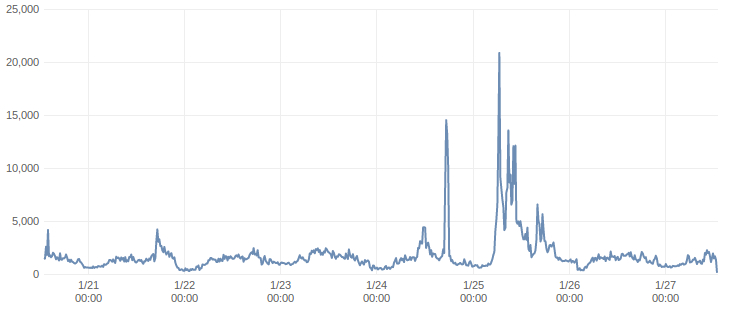
The graph shows two significant spikes and two small spikes. The first one at
15,000 was on 24th January. The second one at 20,000+ was in the day on 25th
January when Epiphany January contest was going on. The spike which just
crosses 5000 in the later part of 25th was for the January Jackpot challenge.
It’s clear that something else was wrong.
We got notification that things were not right and we sprung in action in no
time. We found out that the servers were not sending replies to the requests,
the requests were just sitting idle in queues and waiting for something to
finish. That was the real bottlneck. There was no extra load on the servers,
with their CPU utilization less than 30% at any point of time. The
Status Server was continuously sending
notifications that the requests are getting timed out. And in a situation like
that, throwing extra servers also didn’t help.
####What exactly went wrong
The reason it happened was that we have recently started collecting lots of
data for the users activity on HackerEarth. They will be used in the
Search Engine that we are rolling out this week. I didn’t want to announce
it this way, and there will be separate blog post on its details later. But
here is what happened in the nutshell:
-
We use haystack wrapper for our search, and we had been using the old version of it. It is not threadsafe, throws exceptions non-deterministically for requests. Our Apache server runs in a multi-process and multi-threaded configuration. This issue just exploded in the night.
-
In Django, signals are used to couple different applications. Signals notifies other applications when an application data is changed. Think like, if a user registers on the site you would want to update the search index so that the user can be made searchable now. This happens for each and every object generated on the site, a signal is sent to haystack which does the job then. We figured out it was an overkill, and this was not the right way.
-
We also saw that the servers reported no database connection to our analytics database, but rather rarely. This was something not expected. All the non-AJAX requests are logged in analytics database, and this was something to be worried about.
####What we did
-
We made the haystack thread-safe by using locking mechanisms.
-
We disabled all the unnecessary signals including those of haystack.
-
We have disabled the requests logging for now until we introduce fault tolerance for the analytics database, the resiliency that we have for master database right now. Read more about it.
These incidents remind us to be more careful, make us realize the impact that they have, and we are progressively moving towards a much stable product. Despite of these instances, we are commited to building the best product out there and will continue to do so. You might be interested in reading about the post on Programming challenges, uptime, and mistakes in 2013.
Thank you all for being so patient. We appreciate that, and we are doing our best to not let that happen again.
Let me know if you have any comments, suggestions or anything else.
Posted by Vivek Prakash. Follow me @vivekprakash. Write to me at vivek@hackerearth.com.