HackerEarth API v2: Introducing asynchronous callbacks
We had already published HackerEarth API v1 in February, 2012 at http://developer.hackerearth.com. The API v1 was synchronous in nature. This means that your request kept hanging until the code evaluation was done and response was received. This seriously limited anyone from writing robust applications using the API.
We have been using the asynchronous API for a long time ourselves at HackerEarth for processing all the code submissions. It’s fast, it’s robust and works flawlessly. Today, we are making the async API public.
There is not a major change in the way API request is done, if you have already checked out the synchronous API v1. Now, you get a confirmation response as soon as you do the request. The actual response containing the code evaluation data arrives later at the callback as POST data, with the response contained in ‘payload’ POST parameter. The response format is always same and in JSON format.
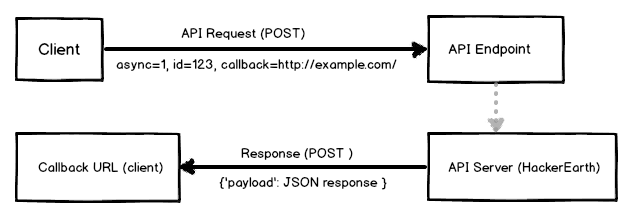
Below is a technical description of how the Asynchronous API works.
The API defines the following endpoints:
http://api.hackerearth.com/code/compile/
http://api.hackerearth.com/code/run/
If you haven’t already got your secret key, register here.
To make an asynchronous request, now you just need to pass 1 as a value to ‘async’ parameter, along with other required parameters.
import urllib
COMPILE_URL = 'http://api.hackerearth.com/code/compile/'
RUN_URL = 'http://api.hackerearth.com/code/run/'
CLIENT_SECRET = '5db3f1c12c59caa1002d1cb5757e72c96d969a1a'
source = open('sample.c').read()
lang = 'C'
post_data = {
'client_secret': CLIENT_SECRET,
# Asynchronous mode on
'async': 1,
'source': source,
'lang': lang,
'time_limit': 5,
'memory_limit': 262144,
# Id to keep track of request
'id': 123,
# Callback URL where processed response will later arrive
# - this response is same as the response received in
# synchronous API request.
'callback': 'http://example.com/receive-hackerearth-response/'
}
post_data = urllib.urlencode(post_data)
response = urllib.urlopen(RUN_URL, post_data)
print "post_data: ",post_data
print
print response.read()
Output from the above script is:
post_data: lang=C&source=%23include+%3Cstdio.h%3E%0A%0Aint+main%28%29+%7B%0A++++printf%28%22Hello%22%29%3B%0A++++int+n%3B%0A++++scanf%28%22%25d%22%2C+%26n%29%3B%0A++++printf%28%22%5Cn%25d%5Cn%22%2C+n%29%3B%0A++++return+0%3B%0A%7D%0A&callback=http%3A%2F%2Fexample.com%2Freceive-hackerearth-response%2F&async=1&time_limit=5&client_secret=4df77c2c2eb62f9adb20bd1127f6f44a4ce6cda4&id=123&memory_limit=262144
{"errors": {}, "code_id": "3d255bX", "id": 123, "message": "OK", "run_status": {"status": "NA", "time_limit": 5, "async": 1, "memory_limit": 262144}, "compile_status": "Compiling...", "web_link": "http://code.hackerearth.com/3d255bX"}
In the asynchronous API, ‘id’ and ‘callback’ are mandatory parameters.
‘id’ is given by client and is returned in the response. It’s also returned
in the response sent later at callback URL. You might have noticed the following
map in the JSON response:
"run_status": {"status": "NA", "time_limit": 5, "async": 1, "memory_limit": 262144}
"compile_status": "Compiling..."
The run_status.status emits ‘NA’, which means the result is not yet available.
The compile_status shows ‘Compiling…’ which means the code compilation has started.
The processing of response received at callback URL given by you in API request can be done as following:
import json
def api_response(request):
payload = request.POST.get('payload', '')
"""
This payload is in JSON format. You need to load it using
native method to convert it into dictionary for easy operations
later on.
"""
payload = json.loads(payload)
print payload
"""
{u'errors': {}, u'code_id': u'3d255bX', u'web_link': u'http://code.hackerearth.com/3d255bX', u'compile_status': u'OK', u'id': u'123', u'async': 1, u'run_status': {u'status': u'AC', u'memory_used': u'64', u'output_html': u'Hello<br>1</br>', u'time_used': u'0.1006', u'signal': u'OTHER', u'status_detail': u'N/A', u'output': u'Hello\\n1\\n'}, u'message': u'OK'}
"""
run_status = payload.get('run_status')
o = run_status['output']
print o
"""
Hello
1
"""
return HttpResponse('API Response Recieved!')
The data is received as POST request, and the JSON response is contained in
payload key of POST request dictionary. request.POST.get(‘payload’)
returns the JSON response.
{u'errors': {}, u'code_id': u'3d255bX', u'web_link': u'http://code.hackerearth.com/3d255bX', u'compile_status': u'OK', u'id': u'123', u'async': 1, u'run_status': {u'status': u'AC', u'memory_used': u'64', u'output_html': u'Hello<br>1</br>', u'time_used': u'0.1006', u'signal': u'OTHER',u'status_detail': u'N/A', u'output': u'Hello\\n1\\n'}, u'message': u'OK'}
payload has id that was sent in the request.
This way you can keep track of the response received at
the callback URL from client side and which response
came for which request if you are sending many requests in batch.
payload also contains the full information about run_status and
compile_status giving you all the data about code evaluation.
Asynchronous API has many advantages with no limit on number of requests per second. You can also build your own website for code evaluation just using the API. If you haven still not got your secret key, click here. For more detailed information, please go through the documentation at http://developer.hackerearth.com. Now build something interesting and dazzle the world :)
Contributions are welcome for improving the documentation of http://developer.hackerearth.com. You can fork the repository at https://github.com/HackerEarth/developer.hackerearth.com and send pull requests. Sample code in multiple languages are highly welcome.
Posted by Vivek Prakash. Follow me @vivekprakash. Write to me at vivek@hackerearth.com.