Continuous Deployment System
This is one of the coolest and important thing we recently built at HackerEarth. What’s so cool about it? Just have a little patience, you will soon find out. But make sure you read till the end :)
I will try to make this post as resourceful, and clear so that people who always wondered how to implement a Continuous Deployment System(CDS) can gain insights.
At HackerEarth, we iterate over our product quickly and roll out new features as soon as they are production ready. In last two weeks, we deployed 100+ commits in production, and a major release is scheduled to be launched within a few days comprising over 150+ commits. Those commits consists of changes to backend app, website, static files, database and many more. We have over a dozen different types of servers running e.g. webserver, code-checker server, log server, wiki server, realtime server, NoSQL server, etc. And all of them are running on multiple ec2 instance at any point of time. Our codebase is still tightly integrated as one single project with many different components required for each server. And when there are changes to codebase, all the related servers and components need to be updated when deploying in production. Doing that manually would have just driven us crazy, and would have been a total waste of time!
See the table of commits deployed on a single day, and that too on lighter day!
With such speed of work, we needed a automated deployment system along with automated testing. Our implementation of CDS helps the team to roll out features in production with just a single command: git push origin master. Also, another reason to use CDS is that we are trying to automate the crap out of everything and I see us going in right direction.
####CDS Model
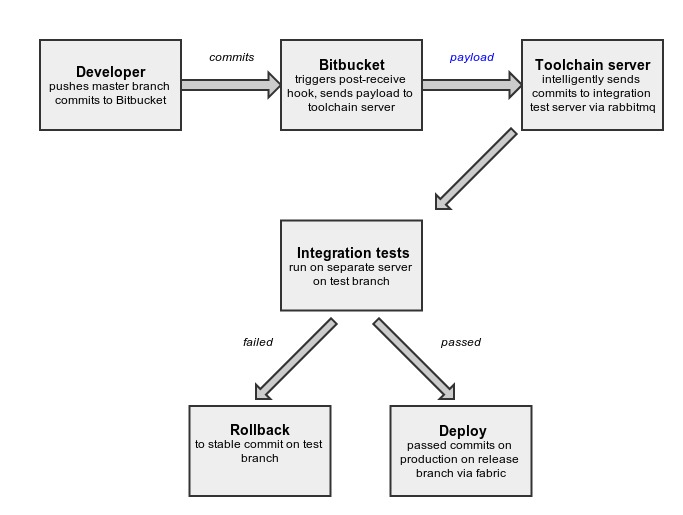
The process begins with developer pushing bunch of commits from his master branch to remote repository which in our case is setup on Bitbucket. We have setup a post hook on Bitbucket, so as soon as Bitbucket receives commits from developer, it generates a payload(containing information about commits) and sends it to toolchain server.
Toolchain server back-end receives payload and filters commits based on branch and neglects any commit other than from master branch or of type merge commit.
def filter_commits(branch=settings.MASTER_BRANCH, all_commits=[]):
"""
Filter commits by branch
"""
commits = []
# Reverse commits list so that we have branch info in first commit.
all_commits.reverse()
for commit in all_commits:
if commit['branch'] is None:
parents = commit['parents']
# Ignore merge commits for now
if parents.__len__() > 1:
# It's a merge commit and
# We don't know what to do yet!
continue
# Check if we just stored the child commit.
for lcommit in commits:
if commit['node'] in lcommit['parents']:
commit['branch'] = branch
commits.append(commit)
break
elif commit['branch'] == branch:
commits.append(commit)
# Restore commits order
commits.reverse()
return commits
Filtered commits are then grouped intelligently using a file
dependency algorithm.
def group_commits(commits):
"""
Creates groups of commits based on file dependency algorithm
"""
# List of groups
# Each group is a list of commits
# In list, commits will be in the order they arrived
groups_of_commits = []
# Visited commits
visited = {}
# Store order of commits in which they arrived
# Will be used later to sort commits inside each group
for i, commit in enumerate(commits):
commit['index'] = i
# Loop over commits
for commit in commits:
queue = deque()
# This may be one of the group in groups_of commits,
# if not empty in the end
commits_group = []
commit_visited = visited.get(commit['raw_node'], None)
if not commit_visited:
queue.append(commit)
while len(queue):
c = queue.popleft()
visited[c['raw_node']] = True
commits_group.append(c)
dependent_commits = get_dependent_commits_of(c, commits)
for dep_commit in dependent_commits:
commit_visited = visited.get(dep_commit['raw_node'], None)
if not commit_visited:
queue.append(dep_commit)
if len(commits_group)>0:
# Remove duplicates
nodes = []
commits_group_new = []
for commit in commits_group:
if commit['node'] not in nodes:
nodes.append(commit['node'])
commits_group_new.append(commit)
commits_group = commits_group_new
# Sort list using index key set earlier
commits_group_sorted = sorted(commits_group, key= lambda
k: k['index'])
groups_of_commits.append(commits_group_sorted)
return groups_of_commits
Top commit of each group is sent for testing to integration test
server via rabbitmq. First I wrote code which sent each commit for
testing but it was too slow, so Vivek suggested to group commits from payload and run
test on top commit of each group, which drastically reduces number of times
tests are run.
Integration tests are run on integration test server. There is a separate branch called test on which tests are run. Commits are cherry-picked from master onto test branch. Integration test server is a simulated setup to replicated production behavior. If tests are passed then commits are put in release queue from where they are released in production. Otherwise test branch is rolled back to previous stable commit, and clean up actions are performed including notifying the developer whose commits failed the tests.
####Git Branch Model
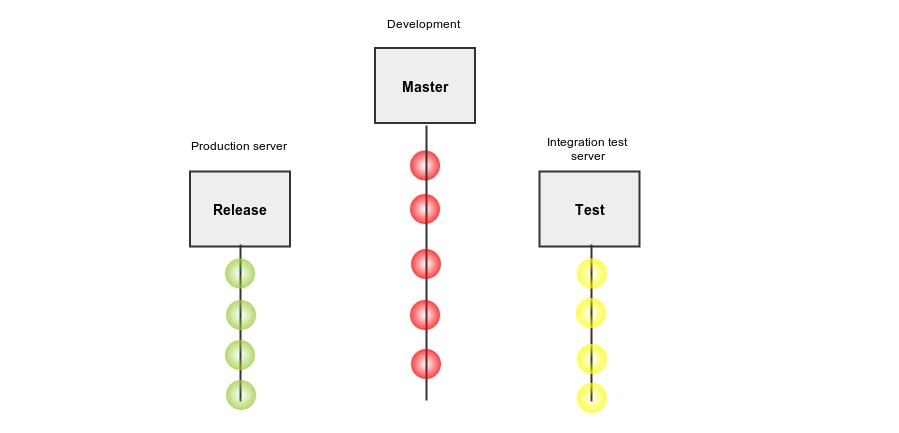
In previous section you might have noticed there are three branches that we are using, namely- master, test and release. Master is the one where developer pushes its code. This branch can be unstable. Test branch is for integration test server and release branch for production servers. Release and test branch move parallel and they are always stable. As we write more and more tests, the uncertainty of a bad commit being deployed in production will reduce exponentially.
####Django Models
Each commit(or revision) is stored in database. This data is helpful in many circumstances like finding previously failed commits, relate commits to each other using file dependency algorithm, monitoring deployment etc.
Django models used are:-
- Revision- commit_hash, commit_author, etc
- Revision Status- revision_id, test_passed, deployed_on_production etc.
- Revision Files- revision_id, file_path
- Revision Dependencies
When top commit of each group is passed to integration test server, we first find its dependencies i.e. previously failed commits using file dependency algorithm and save it in Revision Dependencies model so that next time we can directly query from database.
def get_dependencies(revision_obj):
dependencies = set()
visited = {}
queue = deque()
filter_id = revision_obj.id
queue.append(revision_obj)
while len(queue):
rev = queue.popleft()
visited[rev.id] = True
dependencies.add(rev)
dependent_revs = get_all_dependent_revs(rev, filter_id)
for rev in dependent_revs:
r_visited = visited.get(rev.id, None)
if not r_visited:
queue.append(rev)
#remove revision from it's own dependecies set.
#makes sense, right?
dependencies.remove(revision_obj)
dependencies = list(dependencies)
dependencies = sorted(dependencies, key=attrgetter('id'))
return dependencies
def get_all_dependent_revs(rev, filter_id):
deps = rev.health_dependency.all()
if len(deps)>0:
return deps
files_in_rev = rev.files.all()
files_in_rev = [f.filepath for f in files_in_rev]
reqd_revisions = Revision.objects.filter(files__filepath__in=files_in_rev, id__lt=filter_id, status__health_status=False)
return reqd_revisions
As told earlier in overview section, these commits are then cherry- picked onto test branch from master branch and process continues.
####Deploying on Production
Commits that passed integration tests are now ready to be deployed but
before that there are few things to keep in mind when deploying code
on production like restarting webserver, deploying static files,
running database migrations etc. The toolchain code intelligently decides which
servers to restart, whether to collect static files or run database migrations,
and which servers to deploy on based on what changes were done in the commits.
You might have realized we do all this on basis of types and categories of files
changed/modified/deleted in the commits to be released.
You might also have realized that we are controlling deployment on production and test server from toolchain server(the one which receives payload from bitbucket). We are using fabric to serve this purpose. A great tool indeed for executing remote administrative tasks!
from fabric.api import run, env, task, execute, parallel, sudo
@task
def deploy_prod(config, **kwargs):
"""
Deploy code on production servers.
"""
revision = kwargs['revision']
commits_to_release = kwargs['commits_to_release']
revisions = []
for commit in commits_to_release:
revisions.append(Revision.objects.get(raw_node=commit))
result = init_deploy_static(revision, revisions=revisions, config=config,
commits_to_release=commits_to_release)
is_restart_required = toolchain.deploy_utils.is_restart_required(revisions)
if result is True:
init_deploy_default(config=config, restart=is_restart_required)
All this process takes about 2 minutes for deployment on all machines for a group of commits or single push. This made our life a lot easier, we don’t fear now in pushing our code and we can see our feature or bug fix or anything else live in production in just a few mminutes. Undoubtedly, this will also help us in releasing new features without wasting much time. Now deploying is as simple as writing code and testing on local machine. We also deployed 100th commit in production a few days ago using automated deployment, which stands testimony to the robustness of this system.
P.S. I am an undergraduate student at IIT Roorkee. You can find me
@LalitKhattar or on
HackerEarth.
Posted by Lalit Khattar, Summer Intern 2013 @HackerEarth